
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 알고리즘
- Kakao
- 프로그래머스 #카카오 #IT #코딩테스트
- 파이썬
- 코딩테스트
- programmers
- C
- 백엔드
- 스프링
- Linux
- 프로그래머스
- docker
- Elasticsearch
- 운영체제
- 리눅스
- Spring
- DPDK
- 자바
- 도커
- springboot
- Python
- 개발자
- 네트워크
- 카카오
- Java
- 쿠버네티스
- 캐시
- 엘라스틱서치
- IT
- 스프링부트
- Today
- Total
저고데
[ElasticSearch] 5. 이전 굴욕 만회하기. RDBMS vs ElasticSearch (2) 본문
공통 실험 조건 설정하기
지난 시간에 진행한 실험은 모두(?)의 예상을 깨고 RDBMS가 속도가 더 빠르며, 성능이 더 우수하였다.
굴욕의 이전 실험 과정 보기 : https://justgotothedesk.tistory.com/128
그래서 이를 모면하고자, 이번에는 좀 더 복잡한 데이터를 바탕으로 속도 실험을 진행하도록 하겠다.
아래와 같이, 상품에 대한 데이터를 저장하고 검색해볼 것이며, 데이터의 개수는 이전보다 많은 10만개로 설정하였다.
그리고 각각 "긍정"이라는 단어를 검색했을 때, 걸리는 시간을 비교할 것이다.
PUT /elastic_dw_test
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "nori_tokenizer"
}
}
}
},
"mappings": {
"properties": {
"class_id": {
"type": "long"
},
"brand_no": {
"type": "integer"
},
"benefit_price": {
"type": "long"
},
"link_info": {
"type": "long"
},
"disp_nm": {
"type": "text",
"analyzer" : "my_analyzer"
}
}
}
}ElasticSearch와 RDBMS 컨트롤러 코드는 아래와 같이 작성하였다.
검색 처리를 기점으로 시간을 계산하는 코드를 추가하여, ElasticSearch에서의 검색 시간과 RDBMS에서의 검색 시간을 비교할 수 있도록 하였다.
@Controller
public class ElasticVersusRdb {
@Autowired
private IElasticDwService elasticService;
@Autowired
private ISqlServerService sqlService;
// 검색 페이지로 보내준다.
@RequestMapping(value = "/searchTestEsSql.action", method = { RequestMethod.GET , RequestMethod.POST})
public String searchTestEsSql(HttpServletRequest request, HttpServletResponse response) {
return "/test/searchtest";
}
// RDBMS 를 통해서 검색결과를 가져와준다.
@RequestMapping(value = "/sqlServerTime.action", method = { RequestMethod.GET , RequestMethod.POST})
@ResponseBody
public List<String> sqlServerTime(HttpServletRequest request, HttpServletResponse response) {
String keyword = request.getParameter("search_keyword");
long startTime = System.currentTimeMillis();
List<String> searchResult = sqlService.getSearchData(keyword);
long endTime = System.currentTimeMillis();
long timeElapsed = endTime - startTime;
searchResult.add(Long.toString(timeElapsed));
return searchResult;
}
// Elasticsearch 를 통해서 검색결과를 가져와준다.
@RequestMapping(value = "/elasticTime.action", method = { RequestMethod.GET , RequestMethod.POST})
@ResponseBody
public List<String> elasticTime(HttpServletRequest request, HttpServletResponse response) {
String keyword = request.getParameter("search_keyword");
long startTime = System.currentTimeMillis();
List<String> searchResult = elasticService.getSearchData(keyword);
long endTime = System.currentTimeMillis();
long timeElapsed = endTime - startTime;
searchResult.add(Long.toString(timeElapsed));
return searchResult;
}
}RDBMS 코드 작성하기
그리고 RDBMS의 Service 코드와 Service Implement 코드를 아래와 같이 작성하였다.
단순한 쿼리를 보내는 것이 아닌, "like" 연산자를 활용하여 결과값을 반환하도록 하였다.
public interface ISqlServerService {
List<String> getSearchData(String keyword);
}@Service
public class SqlServerService implements ISqlServerService {
@Override
public List<String> getSearchData(String keyword) {
EntityManagerFactory emf = Persistence.createEntityManagerFactory("sqlserver");
EntityManager em = emf.createEntityManager();
EntityTransaction tx = em.getTransaction();
List<String> resultList = new ArrayList<>();
tx.begin();
try {
String queryString = "SELECT e.dispNm FROM MongoDwDTO e WHERE e.dispNm LIKE :keyword";
resultList = em.createQuery(queryString, String.class)
.setParameter("keyword", "%" + keyword + "%")
.getResultList();
tx.commit();
} catch (Exception e) {
e.printStackTrace();
tx.rollback();
} finally {
em.close();
}
emf.close();
return resultList;
}
}ElasticSearch 코드 작성하기
다음은 ElasticSearch의 설정과 Service, Service Implement 코드를 아래와 같이 작성하였다.
@Configuration
public class ElasticConfig {
@Bean
public RestHighLevelClient restHighLevelClient() {
final CredentialsProvider credentialsProvider = new BasicCredentialsProvider();
credentialsProvider.setCredentials(AuthScope.ANY, new UsernamePasswordCredentials("elastic_id", "elastic_pw"));
RestClientBuilder builder = RestClient.builder(new HttpHost("ip_address", 9200))
.setHttpClientConfigCallback(httpClientBuilder -> httpClientBuilder.setDefaultCredentialsProvider(credentialsProvider));
return new RestHighLevelClient(builder);
}
}public interface IElasticDwService {
List<String> getSearchData(String keyword);
}
@Service
public class ElasticDwService implements IElasticDwService {
private final ElasticConfig elasticClient;
@Autowired
public ElasticDwService(ElasticConfig elasticClient) {
this.elasticClient = elasticClient;
}
@Override
public List<String> getSearchData(String keyword) {
List<String> searchResult = new ArrayList<>();
try {
SearchRequest searchRequest = new SearchRequest("elastic_dw_test");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.size(100); // 결과 데이터 크기를 100으로 설정
MatchQueryBuilder matchQueryBuilder = QueryBuilders.matchQuery("disp_nm", keyword);
matchQueryBuilder.analyzer("my_analyzer");
searchSourceBuilder.query(matchQueryBuilder);
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = elasticClient.restHighLevelClient().search(searchRequest, RequestOptions.DEFAULT);
SearchHits hits = searchResponse.getHits();
SearchHit[] searchHits = hits.getHits();
for (SearchHit hit : searchHits) {
String dispNm = hit.getSourceAsMap().get("disp_nm").toString();
searchResult.add(dispNm);
}
return searchResult;
} catch(Exception e) {
e.printStackTrace();
return null;
}
}
}
검색 결과
기다리고 기다리던, 대망의 성능 결과이다.
1. RDBMS
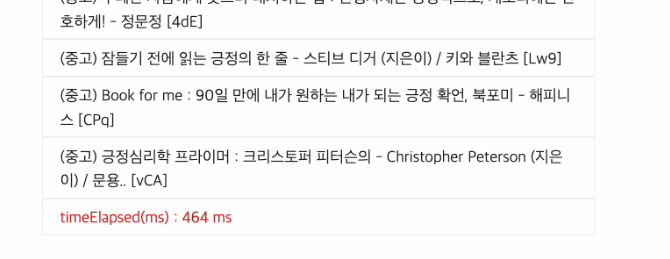
기다리고 기다리던, 대망의 성능 결과이다.
먼저, RDBMS의 경우에는 464ms로 지난 시간에 29ms가 걸리던 시간에 비해, 약 20배 정도 느려졌다.
이전보다 데이터의 양도 약 7배가 증가하고 쿼리문도 복잡해졌지만, 상당히 성능이 떨어진 것을 확인할 수 있었다.
2. ElasticSearch

반면, ElasticSearch 경우에는 28ms로 지난 시간에 82ms가 걸리던 시간에 비해, 3배 이상 빨라졌다.
그리고 RDBMS와 비교했을 때, 약 20배 이상 빠른 속도를 보여준다.
마치며
그렇다면 왜 이전과 다른 결과가 나온 것일까?
내 생각이 맞다면, 이전 실험에서는 데이터의 양도 적고 단순하게 반복되는 패턴을 가진 데이터(temp1, temp2 ...)이기 때문에 발생한 결과이기 때문이라는 생각이 든다.
그렇다면 왜 ElasticSearch가 더 빠른가?
ElasticSearch는 RDBMS와 다르게 scan 작업이 따로 존재하지 않는다.
데이터를 저장할 때, 역인덱스의 형태로 저장하기 때문이다. (이는 추후 따로 블로그에 정리 예정입니당)
그렇다면 단지 속도가 빨라서 검색엔진에서 ElasticSearch을 사용하는가?
당연히 아니다 !
이는 둘의 탐색 방식과도 관련이 있는데, 예를 들어서 "난 최강이다"라는 데이터가 저장되어있다고 보자.
RDBMS와 ElasticSearch 각각에서 이를 뒤집에서 "최강이다 난"이라고 검색을 했다고 하자.
그렇다면 결과는 어떨까?
RDBMS에서는 검색 결과가 "없음"이고 ElasticSearch에서는 "난 최강이다" 데이터를 반환한다.
이 역시도 마찬가지로 ElasticSearch에서는 각 단어별로 분석과 필터링을 거쳐서 역인덱스를 구성하기 때문에 반대로 검색을 해도 이와 비슷한 단어를 찾아준다.
따라서 ElasticSearch를 사용하는 것이다.
아무튼 오늘은 이렇게 지난 시간의 굴욕(?)을 만회할 수 있는 시간이었다 !
ElasticSearch, 반드시 공부해야겠지 ?
'ElasticSearch' 카테고리의 다른 글
| [ElasticSearch] 4. Spring Page를 통해 검색 결과 페이지로 만들기 (1) | 2024.01.31 |
|---|---|
| [ElasticSearch] 3. 검색 엔진을 구현해보자 (0) | 2024.01.30 |
| [ElasticSearch] 2. 관계형 데이터베이스와 엘라스틱 서치 성능 비교하기 (0) | 2024.01.29 |
| [ElasticSearch]1. 스프링부트와 엘라스틱 서치 연동하기 (0) | 2024.01.27 |
| [ElasticSearch]0. 엘라스틱 서치 왜 배우는가? (1) | 2024.01.25 |



